AdaptDL Documentation¶
AdaptDL is a resource-adaptive deep learning (DL) training and scheduling framework, and is part of the CASL open source project. The goal of AdaptDL is to make distributed DL easy and efficient in dynamic-resource environments such as shared clusters and the cloud.
AdaptDL consists of two components which can be used together with or separately from one another:
adaptdl-sched: A cluster scheduler on Kubernetes optimized for distributed deep learning training.
adaptdl: A library for adaptive batch sizes that can efficiently scale distributed training to many nodes.
Some core features offered by AdaptDL are:
Elastically schedule distributed DL training jobs in shared clusters.
Cost-aware resource auto-scaling in cloud computing environments (e.g. AWS).
Automatic batch size and learning rate scaling for distributed training.
AdaptDL supports PyTorch training programs. TensorFlow support coming soon!
Why AdaptDL?¶
Efficient Resource Management¶
The AdaptDL scheduler directly optimizes cluster-wide training performance and resource utilization, by using a genetic algorithm to periodically optimize resource allocations for all jobs. Through elastic re-scaling, co-adapting batch sizes and learning rates, and avoiding network interference, AdaptDL significantly accelerates shared-cluster training when compared with alternative schedulers. For details, please see our OSDI’21 research paper.
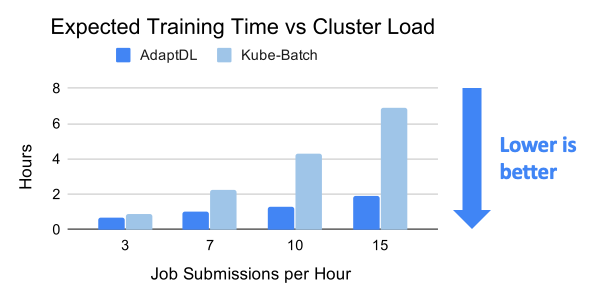
In the cloud (e.g. AWS), AdaptDL auto-scales the size of the cluster based on how well those cluster resources are utilized. AdaptDL automatically provisions spot instances when available to reduce cost by up to 80%.
Adaptive Batch Size Scaling¶
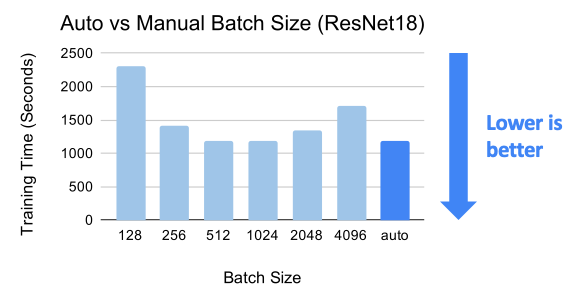
Efficient distributed training requires careful selection of the batch size and learning rate, which can be tricky to find manually. AdaptDL offers automatic batch size and learning rate scaling, which enables efficient distributed training without requiring manual effort. To achieve this, AdaptDL measures the system performance and gradient noise scale during training, adaptively selects the most efficient batch size, and scales the learning rate using AdaScale.
Easy-to-use Elastic API¶
Making training programs run elastically can be challenging and error-prone. AdaptDL offers APIs which make it easy to enable elasticity for data-parallel PyTorch programs. Simply change a few lines of code, without heavy refactoring!
BEFORE:
torch.distributed.init_process_group("nccl")
model = torch.nn.parallel.DistributedDataParallel(model)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=128)
for epoch in range(100):
...
AFTER:
adaptdl.torch.init_process_group("nccl")
model = adaptdl.torch.AdaptiveDataParallel(model, optimizer)
dataloader = adaptdl.torch.AdaptiveDataLoader(dataset, batch_size=128)
for epoch in adaptdl.torch.remaining_epochs_until(100):
...
Getting Started¶
AdaptDL consists of a job scheduler and an adaptive training library. They can be used in multiple ways:
Scheduling multiple training jobs on a shared Kubernetes cluster or the cloud (Scheduler Installation).
Adapting the batch size and learning rate for a single training job (Standalone Training).
As a Ray Tune Trial Scheduler (Tune Trial Scheduler).
As a single training job running on a Ray AWS cluster (Ray AWS Launcher)